IEEE杂志对我校殷绪成教授团队科研成果进行深度报道
近日,IEEE(美国电气电子工程师学会)的旗舰出版物IEEE Spectrum的中文版《科技纵览》杂志,对计算机与通信工程学院模式识别技术创新实验室(殷绪成教授团队)关于复杂文档/图像/视频文本识别领域的大量领先于国际的研究成果进行了深度报道。报道原文如下:
机器识字:复杂文档/图像/视频文本识别新技术
经过多年的科研攻关,北京科技大学计算机科学与技术系模式识别技术创新实验室殷绪成教授团队研制了先进的自然场景/网络图片/复杂视频文本检测与识别创新技术,取得了大量国际领先的研究成果。
复杂文档/图像/视频(如自由手写、历史文档、自然场景、网络图片、复杂视频等)文本识别是利用人工智能与模式识别技术,使计算机能够像人一样认识物理世界与互联网等复杂环境中普遍存在的文字,在文字录入、历史文档检索、数字移动服务、智慧城市、网络内容监控与社会公共安全、互联网+、大数据等方面具有重要的应用价值。经过多年的科研攻关,国内研究者在复杂环境下文本识别方面构建了一系列国际领先的创新技术;特别是在自由手写、自然场景、网络图片等文本识别方面,取得了大量国际顶级的研究成果。
北京科技大学计算机科学与技术系模式识别技术创新实验室(殷绪成教授团队)研制了世界上最先进的自然场景/网络图片/复杂视频文本检测与识别创新技术,在2013年国际文档分析与识别技术竞赛中,荣获“自然场景文本检测”、“网络图片文本检测”和“网络图片文本提取”三项冠军;最近,在2015年国际文档分析与识别技术竞赛中,又荣获“自然场景文本端到端识别(通用类)”、“网络图片文本端到端识别(通用类)”、“视频文本检测提取”等四项冠军,引起了国内外学术界及产业界同行的广泛关注。
复杂文档/图像/视频文本识别是当前文档分析与识别、模式识别等领域的重要发展方向,以具有重大社会与经济价值的历史文档检索及文化保护、互联网图片与视频内容安全、移动服务与智慧城市等应用为背景,以复杂环境下的文档与图片为对象,利用模式识别、机器学习(深度学习)、图像处理、计算机视觉等先进技术,使得计算机像人一样分析、提取、识别和挖掘图像中的文本信息。通常,复杂环境下文本识别可以分为两大类别:复杂文档(历史文档)/自由手写文本识别,和自然场景/网络图片/复杂视频文本识别。
基于扫描图像的历史文档/自由手写文本识别,其任务是对复杂文档图像进行版面分析,提取文本区域,从而进行精准的文字识别,在个人笔记、档案、历史文档、票据的数子化方面具有重要的应用前景。历史文档/自由手写文本识别,其技术的挑战性主要来自于历史文档本身的高度复杂性和自由手写文本本身的多样性。
而基于拍照或人工生产等的自然场景/网络图片/复杂视频文本识别,则是从高度差异及异构的图像/视频中检测、提取并识别文本信息。具体的,自然场景文本识别是利用人工智能与模式识别技术,使计算机、智能手机等能够像人一样认识自然界中普遍存在的文字,在数字移动服务、信息检索、智慧城市等方面具有重要的应用价值。网络图片文本识别同样也是利用人工智能与模式识别技术,使网关、计算机等自动识别提取出互联网中海量图片与视频中的文字信息,并进行相应的内容智能分析,在网络内容监控与社会公共安全、互联网+、大数据等行业中具有重要的应用前景。
自然场景、网络图片和复杂视频中的文字识别大大难于传统扫描文档中的文字识别,因为它们具有极大的多样性和明显的不确定性,诸如多语言文字、不同的文字大小、不同的字体、多样的文本与背景颜色、多变的光照与亮度、不一致的对比度与分辨率、多方向与形变文本、复杂的图像背景等。所以,传统的应用于扫描书刊报纸等文档图像的OCR技术在自然场景与网络图片文本识别中具有巨大的局限性。近十年来,国际国内模式识别、文档分析与识别、计算机视觉等领域的众多科研机构(如斯坦福大学、牛津大学、中国科学院自动化研究所、清华大学、北京科技大学等)和大量IT工业界巨头(阿里巴巴、腾讯、百度、Google、Microsoft、Amazon等)都对自然场景/网络图片/复杂视频文本识别技术进行研究与攻关。
经过多年的科研攻关,以中国科学院自动化研究所刘成林研究员、清华大学丁晓青教授、北京科技大学殷绪成教授等为代表的国内研究者在复杂环境下文本识别方面构建了一系列国际领先的创新技术;特别是在自然场景、网络图片、复杂视频等文本识别方面,取得了大量国际顶级的研究成果。
自然场景/网络图片/复杂视频文本识别新技术与新突破
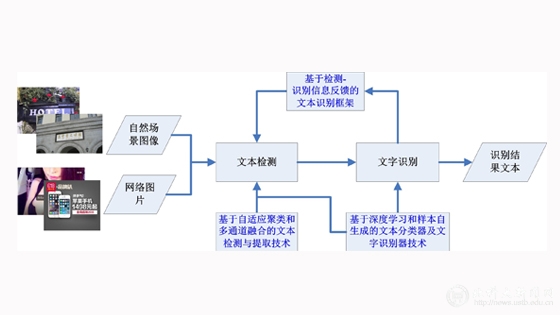
自然场景、网络图片和复杂视频(帧)文本识别技术主要分为两个阶段:首先是对图片中的文字进行检测与提取,输入的是原始图片而输出的是文本区域,即文本检测;然后,对检测出的文本区域进行识别,输入的是文本区域而输出的是结果文字,即文字识别。如果一个系统,输入的是原始图片而输出直接为最终识别的结果文字,则称之为端到端识别(End-To-End Recognition)技术。
当前,绝大部分研究者要么关注文本检测,要么关注文字识别,没有形成良好的端到端识别技术,没有很好的利用识别与检测之间丰富的共享信息和反馈信息。如何对自然场景/网络图片/复杂视频进行有效的文本检测、识别(特别是端到端识别),一直都是学术界和工业界共同关注的重点与难点。北京科技大学计算机系模式识别技术创新实验室(殷绪成教授团队)针对自然场景、网络图片和复杂视频文本识别相关核心技术问题,近几年在文本检测、文本提取、文字识别等各方面进行了持续攻关,提出了先进的自然场景与网络图片文本(端到端)识别统一框架,研制了一系列领先的自然场景与网络图片文本识别新技术(图4)。
自然场景与网络图片文本识别技术新进展
(1)基于自适应聚类和多通道融合的文本检测与提取技术
在自然场景与网络图片等复杂环境下的文本检测,一般都利用连通域分析或图像分割技术等提取候选字符块,然后利用聚类算法把这些候选字符块聚成文本块。在这些方法中,主要涉及三个核心问题:1)字符块提取中,如何利用多通道的信息尽可能的检测出复杂背景中的文字块;2)相似性度量中,如何考虑不同特征的不同影响力,即如何选择相似度计算特征的权重;3)聚类计算中,如何针对实际文本块数目确定聚类数目。在以往的方法中,往往把这些问题分割起来进行处理。不同的是,基于尺度学习的自适应聚类和多通道融合的文本检测新技术,同步学习相似度特征权重和聚类数目,能够快速、鲁棒、精确的检测与提取出图片和视频中各种各样的文本。
(2)基于深度学习和样本自生成的文本分类器及文字识别器技术
近几年火热的深度学习技术,同样也流行于文本判别器和文字识别器构建中,在复杂场景下文本检测与识别中发挥了重要的作用。然而,深度学习都是基于较大规模数据来进行训练的,在小数量样本集上的学习依然是一个挑战性的难题。在自然场景与网络图片中,由于多语言文字、不同的字体与大小、多样的文本颜色与光照等诸多挑战,需要更大规模的训练数据;如何采集整理与深度学习相匹配的有效训练数据,已成为文本检测与识别深度学习技术的核心问题之一。巧妙的是,新技术根据少量真实样本,自动生成大规模训练样本,设计基于深度学习的文本分类器及文字识别器,能够精确的识别自然场景与网络图片中各式各样的文本。
(3)基于检测-识别信息反馈的文本识别框架
如何分析并克服自然场景与网络图片文本检测与识别的主要困难,充分利用端到端识别系统中检测、识别一系列过程信息共享和反馈,是业界攻关的主要技术方向。新技术基于检测-识别信息反馈,构建统一的信息共享和反馈文本识别整体框架,通过文字识别信息来优化文本检测,并以改进后的文本检测提升文字识别效果,较大幅度的提高了端到端场景文本识别系统的整体性能。
基于多年的研究工作和上述的创新成果,殷绪成教授团队研制了世界上顶级水平的自然场景/网络图片/复杂视频文本识别技术,数次荣获国际文档分析与识别大会技术竞赛多项冠军。特别的,荣获了2015年国际文档分析与识别技术竞赛最受关注的“鲁棒阅读竞赛” “自然场景文本端到端识别”、“网络图片文本端到端识别”、“视频文本检测提取”等四项冠军。本届国际文档分析与识别技术竞赛包括了图像与视频文本识别、历史文档图像理解、多语言文字识别与手写鉴别等相关的十一个竞赛单元,吸引了来自中国、美国、德国、法国、英国、日本、韩国、印度等几十个国家一百多支模式识别、文档分析与识别、计算机视觉等领域高水平参赛队伍。
殷绪成教授团队的创新技术,在2015年国际文档分析与识别技术竞赛最具代表性和通用性(无字典约束)的“自然场景文本端到端识别”和“网络图片文本端到端识别”中,双双荣获第一名。在无字典约束的情况下,殷绪成教授团队将自然场景下端到端文本识别精度提升到了81.74%,综合性能(f-score)提升至75.29%,比竞赛第二名的团队高出了十来个百分点,比上一次(2013年)国际文档分析与识别大会论文公开的结果足足提高了将近一倍;同时,殷绪成教授团队的网络图片中端到端文本识别精度和综合性能(f-score)分别高达80.97%和76.98%,而竞赛第二名的团队只有57.35%和57.01%。值得期待的是,这些文本检测与识别的创新技术,将极大的推动模式识别、文档分析与识别、OCR技术在自然场景、网络图片、复杂视频等环境下的重要发展及广泛应用。
复杂文档/图像/视频文本识别应用新天地
通过几十年的文档分析与识别持续研究,特别是最近几年的模式识别、机器学习等新技术与新手段的涌现,复杂环境下的文本识别理论、方法、技术与系统等各方面取得了重要的突破,复杂文档/图像/视频文本识别技术将迎来应用的新天地。
从“线下”走进“网上”(自由手写文本识别):诸如,每次工作会议后,无需再把白板上的讨论内容抄写下来,只要将白板用手机等智能设备拍照留存,并对其中的自由手写文本及图片进行识别,系统便能自动识别并分检出相关人员的后续工作,并将待办事项自动存放到各自的电子日历中。
让“自然界”融入“信息界”(自然场景文本识别):诸如,把手机摄像头对准菜单上的英文菜名,屏幕上实时显示出翻译好的中文菜名;从车载摄像头所拍摄的街景中自动提取并识别文字,让地图信息更丰富更准确,进行精确的导航;戴着智能眼镜在超市购物,看到心仪商品上的文字,能自动搜索出商品的详细信息。
把“净化器”、“瞄准器”移至“互联网”(网络图片/复杂视频文本识别):诸如,网络社交APP中的图片与视频内容传输与发布时,网关实时检测识别图像中的不良文本信息并进行内容管理,构建一个健康干净的互联网大数据环境;富媒体移动通信网络中,计算机对图像、视频类多媒体的不良信息内容进行自动化识别与分类检索,确保通信通畅与数据安全。在互联网+电商平台上,自动识别海量图片/视频中内嵌的文本信息,进行商品的精准搜索和用户的个性推荐。
另外,传统的文字识别技术应用,比如票据识别、邮政地址识别、手写档案和历史文档数字化,过去由于技术制约,长期得不到规模化应用。现在,随着新一代文字识别技术的发展和性能提升,这些人们长期期待的传统应用有望迎来新一轮应用的爆发。
(责编:邢华超)

